前面的几篇博客反响还不错,但还有一个硬伤,“说了这么多理论,能不能实践?”讲类似概念的文章不算多,但也不少了,但我一直没能从中收获太多的东西,反而更是云里雾里的糊涂了。估计这主要是两方面的原因造成的:我智商低,却爱较真!
你说得得天花乱坠,我只信一点,眼见为实,“是骡子是马,牵出来溜溜?”
按照你说的架构,把系统搭起来,跑起来,需求改上个几百上千遍,高并发大流量冲一冲……咦,这样一番折腾下来,没被砸跨,系统千锤百炼之后,还百炼成钢绕指柔。那我才竖起大拇指,真是不错!
我相信,按照DDD、TTD、敏捷开发之类的理念,一定有成功的案例,不然他们不会被站在巅峰的技术大牛们交相称赞。但很遗憾,我这个野生程序员,没机会融入那个圈子。
所以我就用了一个最蛮最笨的方法:我自己做一个系统,严格按照我自己对于这些概念的理解进行开发,看最后这条路能不能走出来?历经五年甚至更多时间的摸索和实践,我觉得我基本上是走出来了。
所以,如果你愿意,就静下心来,听我细细道来吧。
尴尬
在确定了忘记数据库的大原则之后,我们理应从业务层入手开始系统的搭建。
- /*
- 为什么不是从UI层开始?不要笑,我还真记得,有看到过对这种做法的总结和推荐,还有一个什么专有名词,大概就是“页面驱动”之类的。
- 而且你静下心想一想,我们很多的开发实际上就是这样做的!确定方案之后,美工出效果图,前台切图出静态页面,程序员改成动态的,一页一页的做。
- 任务考核就大概是这样的,“我们今天把某个页面做完”。
- 这种做法的好坏利弊我们就不展开了。但如果你一定要一个不从UI层开始的理由,我觉得最有力的就是:我们系统要做三个版本,电脑桌面页面、手机页面和手机APP。
- */
业务层里,通常我们就把需求里的一些名词拎出来,做成一个一个的类,以创业家园为例,就应该有一个博客类(Blog),博客里还有方法,比如GetBlog(int Id),或者GetBlogs(int pageIndex, int pageSize),如下所示:
- class Blog
- {
- string Title { get; set; }
- string Body { get; set; }
- Blog Get(int Id)
- {
- return new Blog();
- }
- IList<Blog> GetBlogs(int pageIndex, int pageSize)
- {
- return new List<Blog>() { };
- }
- }
这是我最开始接触三层架构时业务层类的样子,写在书上的。
但我就感觉这种做法特别别扭!一个博客对象取出10篇博客,一辆汽车具有提供十辆汽车的能力。这都是些什么乱七八糟的东西?不通啊……
我曾经想过将所有的Get()方法设置成静态的,这样从逻辑上说稍微通畅一点:通过博客类可以获取一些博客实例。但还是不爽,类的静态方法就丧失了对象的继承多态等特性。比如,取10篇文章,和取10篇博客就无法重用。
后来我才慢慢明白了,这种做法其实还是来自于“数据库驱动”的思想。Blog类其实代表的是数据库中Blog表,一个Blog实例就代表着一行数据,然后通过该表取到一些行,这些行又被封装成Blog类(细究起来还是很乱,是吧?)。估计当初微软DataSet的流行加剧了这一现象,当然DataSet本身没有问题,它的逻辑是自洽的;然而有很多开发人员不认可DataSet,说它性能低,要用DataReader,自己“封装”,结果不知怎么的,就搞成了上面那种样式的“四不像”。
Entity
上述传统的业务层架构,除了逻辑上的混乱以外,还有一个很大的问题:难以测试!和数据库搅在一起,怎么测试?我是头都大了。我得去做一个小型数据库啊?而且这个数据库还得insert/update之类 的,测试的基准数据就会变,所以每一次单元测试都得tear down(回到基准测试环境),这个又怎么搞?
- //当然,后来我还是找到了混合数据库的测试方法,但我很高兴当时我对数据库的测试完全绝望的状态。因为这促成了我的“忘记数据库”的构想和实践
所以我就在想,能不能把数据库的操作隔离出来?这个时候,我应该是已经开始接触ORM了,他们的操作方式给了我启迪:关系数据库的“增删改查”中“改”没了。改(update)被“异化”成:取出(Load) -> 修改 -> 再存储(Savae)的过程(可参考《忘记数据库》中的例子)。所以,我们是不是就可以首先把“改”独立出来?通过不断的演化,我最后形成了一个Entity的project,负责且仅负责对象状态的改变,而完全不涉及对象的加载存储等功能。
这样做最大的好处,就是解决了Entity的单元测试的问题。由于(至少是暂时)不再需要考虑这些对象和存储问题,那么在测试的时候,我需要一个对象,只需要直接new一个就行了,而不是从数据库里取,这多方便啊!
Query(Repository)
那么,对象的增删查怎么办?从技术层面来讲,我们只能依靠ORM工具了,我用的是NHibernate。简单的说,通过NHibernate,我们可以在对象和数据库结构中建立关系(映射)。然后,可以通过NHibernate的session,调用session.Save(), session.Delete(), session.Load()和session.Query()等方法将对象存储、删除或者加载/检索到内存(C#项目)中使用。
- /// 为什么是NHibernate?
- /// 1、我的项目开始得比较早,好几年前了,应该是。当时Entity Framework还很不成熟,所以没有办法,只能选择NHibernate
- /// 2、我想看一看微软框架以外的世界。其实后来我就知道了,在Java世界,我的这些做法已经差不多是主流了,所谓的SSH之类的。当然,对Java世界我也研究不深,可能也有差异。我的这个框架是自己摸索出来的,觉得够用就好。
但从系统架构层面讲,有另外一种提法:Repository模式。
Repository,从字面意义上理解,就是仓库。这个概念我觉得很贴切,就像汽车存放在库房里,我们通过仓库管理员,取出一辆或多辆汽车。这就有“代码映射真实世界”,一种逻辑自洽的感觉;而不是之前,一辆汽车取出十辆汽车的样子。
具体到代码层面,就大概是这个样子:
- class BlogRepository
- {
- IList<Blog> GetBlogs(int pageIndex, int pageSize)
- {
- return new List<Blog>() { };
- }
- Blog Get(int Id)
- {
- return new Blog();
- }
- }
但Repository的理解和使用都有争议,主流的大概有两种:
1. 认为Repository是类似于集合,或者一种封装集合的对象。所以还是把它放到了Entity中使用。
2. 认为Repository是“聚合根”的一种,和取出/存储对象并列,应该置于Entity之外。
我连Repository都没有显式的使用,所以就不进行这种关于概念的抽象讨论了。后面有机会我们穿插着讲一讲吧。
我们“增”和“删”直接利用了NHibernate的session机制,只是把“查(select)”给单独抽象了出来,也单独的抽象成一个名为Query的project。
Service
好了,现在我们可以回头归纳一下。对系统数据的操作,我们脑海中应该是这样一个概念:
前提:所有的对象平时都是直接的存储在磁盘里,然后:
1. 我们需要某个/些对象时,就把他们从磁盘里取出来,加载到内存中
2. 进行一些操作修改
3. 最后再存储到磁盘中
那么问题来了,上面这些步骤,由“谁”来做呢?注意我们现在所说的这些东西,都是在业务层的范畴。所以,按照三层架构的思路,应该是UI层调用BLL层,而我们的UI层,采用的是MVC,所以,这样工作,是不是应该在Controller里面做?
但是,阅读我们的源代码,你就会发现,我们在UI层和BLL层之间加了一个Service层。实际上是由Service层来做的这些加载、修改和存储的工作。我非常同意这么一个观点:绝不能为了分层而分层。那么,Service层存在的意义是什么?
主要是为了前后端分离。早期的开发过程中,我设想过招聘一个专门的前端开发人员,他/她不管后台的具体业务逻辑、和数据库的交互,只管页面的呈现和交互。那么这里就有一个问题,我不想她只是一个单纯的美工,画出效果图切片弄成一个html的静态页面就完了,我希望她一样的用VS进行开发,用Razor做成view,还负责页面的交互和跳转,所以她还得在Controller里建Action,在Action里写代码。所以她在Action里写代码,是要得到数据用以呈现的,是需要根据页面回发的数据调用不同的业务逻辑的。那么,这些数据这些调用怎么得来?等着后台开发人员完成了之后再做?这无疑是很不经济的。
所以我们抽象了一个ServiceInterface,前台和后台开发人员可以先确立一系列的接口,然后各自去完成自己的实现。于是就有了:
1. UIDevService:前台开发人员的“模拟”实现,看源代码就可以发现,里面是一些非常简单粗暴的逻辑。比如需要一个ViewModel对象,就直接给new一个就可以了。
2. ProdService:真正的业务逻辑实现,是一直连到数据库的。
这其实就有一点“面向接口”的意思,前台后台都依赖于ServiceInterface的接口,而不管其具体的实现。
- // 从这里我们就可以看出来,复杂的架构是一种无奈的选择。
- // 如果我们的所有开发人员都是全栈级别的,可以从效果图一直插到数据库,我们可能就根本不需要这么麻烦。
- // 而现实的情况是,而大部分的开发人员,都有他们的专攻方向;全栈程序员毕竟太少了。
当然,这样隔离出UIDevService之后,还附带了其他一些好处,比如更便利的单元测试。这些我们都以后再说。
上张图吧。先看看,看不懂也就算了,实在是我画得不咋的。以后还会详细讲的:
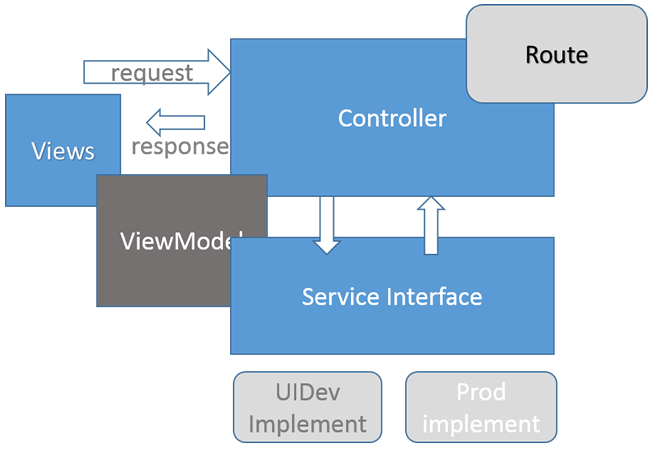
ViewModel
我们项目中还有一个ViewModel,我们的开发人员曾不止一次的提出来:为什么不能直接使用Entity呢?
我非常理解他的疑惑,一次次的把一个Entity里面的Article的属性取出来,再一条条的放到一个ArticleViewModel里面去,这多闹心啊?吃饱了撑的?
其实,我也是开发人员,这框架是我一个字母一个字母敲出来的,能偷懒的我肯定都会偷懒!就像前面我没采用Repository一样,我甚至都还弄过两层架构,但最后都没有好下场,才一步步走到今天。简单的说,ViewModel存在的原因主要有两个:
第一、前后端分离的要求。如果直接使用Entity,前台开发人员是不是又得等着后台开发人员把Entity先建好?是不是Entity一有变动就会立马影响前台开发?有兴趣的同学可以观察我们的ui.task.zyfei.net.sln解决方案,BLL层里的所有project是根本就没有包括在里面的,我们彻底的做到了物理隔绝!
第二、ViewModel和Entity其实是不能100%对应的。尝试过的同学都应该明白。比如我们创业家园项目里有“最新发布博客”的列表小方块,它是一个博客的集合,你怎么弄?你说我可以使用IList<Blog>;但这个小方块里还有一个逻辑:如果当前用户是博客博主,显示修改链接。所以需要“当前用户”的数据,你又怎么把这个数据弄进来?当然,这是一个很大的命题。你肯定可以通过各种手段做到,最简单的就是使用ViewBag。混合ViewBag和Enitty,几乎可以解决所有问题,但有时候太丑陋了!
最后,我们其实应该跳出来,从架构的角度来思考这个问题。ViewModel究竟是什么?它说承载的职责应该是什么?应该由谁来构建它?……
我认为:ViewModel本质上就是一个用于页面呈现的数据容器(DTO),所以他不应该具有任何内在逻辑,而且应该由前端开发人员来构建它。前端开发人员应该彻底的摆脱业务层中的Entity的束缚,根据页面的呈现规律,大胆的进行各种抽象组合,使得ViewModel真正的绽放它的光彩!
MVC
说完了上面这些,MVC其实也就没什么好说的了。就是Controller调用Service,得到ViewModel供View使用这样一个流程。当然,里面有很多值得细讲的内容,比如mvc route的测试、使用Autofac切换Service的实现、Session Per Request进行性能优化等。我们在之后的分则里细讲。
这里还是上一张我制作的PPT吧,丑了点,先将就看吧!
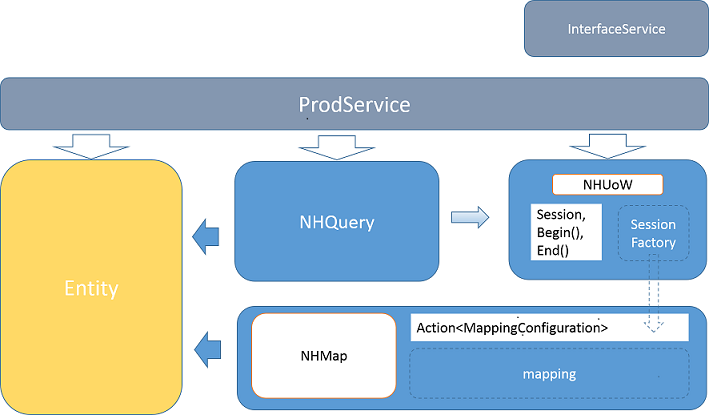
Tool
看过源代码的同学肯定也注意到了项目里有一个Tool的项目文件夹。里面最重要的,就是BuildDatabase项目。这个项目,肩负了构建开发和集成测试数据库的双重责任,还有帮助生成环境数据库更新的作用,是测试驱动的有力保证。可参考(文档可测试化)
要填的坑
框架就这么拉出来了,但其实里面的坑还有很多,趁着有思路,先挖出来,以后慢慢填:
1. UI
• CurrentUser的处理:也是一个相当头痛的东西,因为会大量使用,那么就想着要重用,要想重用就伤脑筋
• Get-Post-Redirct模式:里面也是一堆的坑。因为Http是无状态的,所以Redirect的时候就面临着一个传递数据的问题
• MVC Route:曾经伤心欲绝,当页面复杂之后,url就跳不到指定的action;或者稍一改动,以前的route规则就就崩溃了
• Partial View、EditTemplate和Child Action:在里面不知道晕了多久
• 单元测试
• 其他性能优化
2. Service
• 提高性能:SessionPerRequest。这个必须放在最前面说,因为它深刻的影响了我们下面提到的页面架构的很多东西
• UIDev和Prod的切换:利用Autofac
• SessionPerRequest的具体实现,和UI和NHibernate都搅在一起,真不知道该放在哪里说
• 为什么不使用Repository模式而采用Query
• ViewMode的Map:使用Automapper
• 单元测试:Query又要搅到数据库,唉……
3. BLL
• Entity大集合的性能问题。由于对象间的1:n的关系映射,造成一不小心,就扯出一堆集合数据出来,比如一个Author的所有Article,一个Article的所有Comment、Agree和Disagree。要这样弄的话,再多的内存也吃不消。
• Entity的多态应用。超级大坑,简直是要出人命的感觉,我觉得我能爬出来都是个奇迹
• Entity的单元测试。由于Entity之间复杂的对象关系,其单元测试简直就是一场灾难
• Entity的NHMap单元测试。Entity里都没问题了,但你怎么保证Entity的数据库映射时正确的?只能做单元测试,还是绕不开数据库!
4. Tool
• BuildDatabase:超级繁琐超级难
• 其他清理统计工具等
呵呵,原来有这么多坑!
这又让我不由得想起我烦躁咆哮,扯头发摔鼠标的那些日日夜夜,我也不止一次的怀疑过,我是不是走错道了?这些乱七八糟的MVC、测试驱动、面向对象……根本就没有让我更高效顺畅的开发,好像只是不断的在扯我的后腿。我就用传统的办法,拖控件增删改查数据库又怎么啦?不是一样能用?而且说不定早就开发完了!……
但一次又一次解决问题的喜悦,一不小心窥视到另一个世界的惊奇,让我欲罢不能。这可能就是技术路,人生路,大抵也如此吧?

发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。